
Per chi segue i blog inglesi e chi ha seguito fast forward di qualche settimana fa, Io (Andrea Scarpetta) e Cesarino Morellato, abbiamo pubblicato i risultati di un esperimento che abbiamo fatto nei mesi scorsi, in cui abbiamo cercato di capire se il click sui risultati di Google influenzava il posizionamento.
La nostra analisi è stata pubblicata in inglese su search engine land, oggi vi proponiamo la versione italiana di quell’articolo con qualche dettaglio in più e con qualche dato aggiornato.
Le origini
Molti mesi prima del test, Cesarino aveva dovuto fare un lavoro di “online reputation” per un cliente. Questo genere di attività, come immaginate, comporta una manipolazione della pagina dei risultati su un brand, cercando di sostituire risultati obsoleti con altri più recenti.
Durante questa operazione, un paio di risultati si rivelarono parecchio ostici: erano articoli di giornale pubblicati attorno al 2005-2006, che seppure senza link esterni, occupavano delle posizioni privilegiate in serp grazie all’autorità dei siti di giornale.
Ricordando diversi test in cui si menzionava la possibilità dell’influenza del ctr sui risultati, Cesarino decise di usare dei sistemi di micro-jobs (tipo Amazon Mechanical Turk) per far cliccare sulle digital properties sotto il suo controllo a diverse persone.
Nel giro di poche settimane, le digital properties avevano superato e scalzato gli articoli di giornale.
Il test
A questo punto Cesarino mi ha coinvolto per studiare un esperimento con il quale dimostrare una volta per tutte se il click-through-rate poteva influenzare il posizionamento.
Dopo alcune settimane siamo arrivati allo sviluppo di uno script python che ci ha permesso di ottenere un esperimento con queste caratteristiche:
- Uso di un servizio di Proxy, che tramite apposite API, ci metteva a disposizione migliaia di proxy sul territorio americano.
- Abbiamo raccolto 500 user-agents differenti, che abbiamo utilizzato con rotazione casuale. Gli user-agents erano un mix di desktop, tablet e mobile, con varie versioni di browser, presi da siti esistenti in modo da avere un campione reale.
- Il software cercava di simulare una vera navigazione: quindi apertura di una sessione su google, immissione della query di ricerca, click sulla url selezionata, visita del sito. Per la natura del sistema di proxy, la sessione rimaneva aperta 10 secondi dopo la fine della navigazione, anche se noi a quel punto avevamo già aperto 2-3 sessioni con ip differenti. Dal punto di vista del motore è come se fossimo rimasti sul sito per un tempo indefinito.
- Nel 95% dei casi gli IP sono stati unici nel corso della giornata e quando sono capitate delle ripetizioni non erano mai consecutive.
- Abbiamo fatto un numero casuale di richieste durante i 7 giorni del test, tra 250 e 750 query su google.com, con un numero di connessioni contemporanee tra 2 e 4.
La scelta del bersaglio
Sappiamo che google usa centinaia di fattori per calcolare il ranking di una pagina, per cui abbiamo cercato di isolare delle caratteristiche che ci permettessero di comprendere con la maggior precisione possibile, se la nostra azione aveva o meno dei risultati.
Dopo un lungo dibattito e alcune settimane di osservazione siamo arrivati a selezionare queste caratteristiche:
- Una query obsoleta che non avesse traffico attuale (collegata alle olimpiadi del 2002, di 14 anni fa)
- Che avesse un file PDF nei primi 10 risultati (in questo modo abbiamo escluso la quasi totalità dei fattori onsite, non avendo un sito web da analizzare)
- Che avesse pochi o zero link entranti
- Che fosse parte di una serie di risultati abbastanza stabile
- Che fosse tra la ottava e la decima posizione nei risultati
- Che fosse parte di una pagina di risultati che non avesse elementi universal (video, immagini, eccetera)
Per monitorare l’andamento abbiamo usato due metodi distinti, in modo da essere maggiormente accurati.
- Un servizio di tracking online chiamato proranktracker.com , che faceva una analisi giornaliera dei risultati
- La lettura della posizione cliccata in serp dallo script. La raccolta di questo dato ha portato una informazione aggiuntiva che non ci aspettavamo.
I risultati (aggiornati al 7 settembre 2015)
La nostra operazione di click simulato è durata una settimana e come si vede dal grafico la posizione della URL è passata dalla decima alla terza.
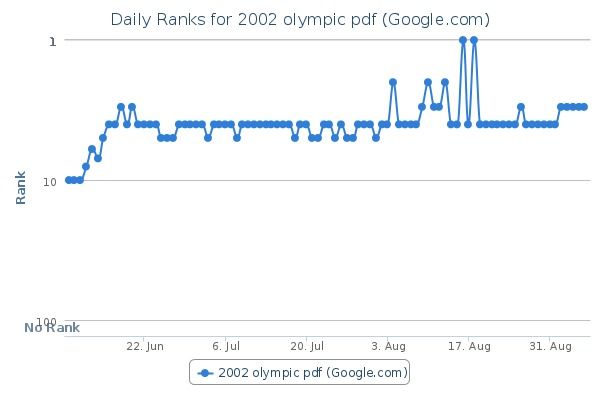
Come si vede la posizione è poi oscillata tra la quinta e la prima, ma senza mai tornare ai livelli originali.
Non eravamo comunque sicuri del grafico di proranktracker: i risultati del motore tendono a cambiare parecchio, in base ad una moltitudine di fattori come la posizione geografica o il device usato. Di questa cosa mi ero già accorto quando avevo usato il Google tag manager per registrare su analytics la posizione cliccata su google. (articolo del 2013) Non sapendo dove era situato il server di proranktracker non potevamo essere sicuri del risultato.
La scoperta (quasi) inaspettata
La lettura del dato cliccato invece ci consentiva di avere un tracciamento realistico e inaspettatamente abbiamo scoperto qualcosa di più…
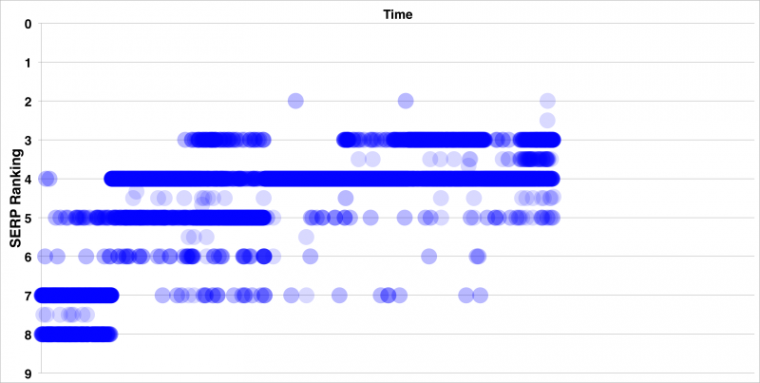
Come si legge questo grafico ?
- Da sinistra verso destra c’è la barra del tempo, considerate che questi sono dati raccolti in soli 6 giorni di tempo, perchè purtroppo il primo giorno il tracciamento della posizione non funzionava e ci manca quel dato (che dovrebbe essere in posizione 8-10 comunque).
- Dal basso verso l’alto c’e’ la posizione rilevata, dalla ottava alla prima.
- I punti più scuri indicano la frequenza della posizione con cui è stata trovata la url. Quindi un punto “trasparente” è una posizione rara.
- come si può notare la frequenza dei posizionamenti aumenta in maniera distinta e si mantiene costante durante il test, con però una serie di risultati intermedi che sono sempre meno frequenti ma mai completamente assenti.
Le conclusioni post-esperimento
Tanto per cominciare, il controllo dei posizionamenti non può essere considerato una metrica o un dato uniforme nel tempo. Questo test dimostra che varia in maniera troppo casuale per essere considerato un dato affidabile: è una sorta di “diagnostica” e come tale andrebbe considerata.
Anche dopo l’esperimento, non possiamo dire che il ctr influenza il processo di “ranking” dei risultati, però come suggerito da Aj kohn e come ribadito nel brevetto depositato da Google (poco dopo il nostro esperimento, segnalato da Seo-by-the-sea), si potrebbe trattare di una sorta di coefficiente che “modifica” la posizione visibile per l’utente finale.
Quindi ci aspettiamo che questo coefficiente, pensato per mettere in evidenza argomenti di interesse temporaneo, prima o poi si sgonfi e la posizione del documento pdf ritorni al suo livello normale.
Un altro esperimento…(non fatto da noi)
In agosto, pochi giorni prima del nostro articolo, è stato pubblicato un altro articolo in cui era stato effettuato un test più massivo, senza risultati di sorta.
Cosa non ha funzionato, secondo noi:
- l’altro esperimento cercava di influenzare dei risultati organici di query molto più complesse ( per esempio “negative seo”, dove c’era Moz in prima posizione)
- La metodologia era discutibile, i clickbot andavano anche fino alla dodicesima pagina per cliccare, sfalsando completamente il comportamento medio degli utenti su google
- E’ stato usato solo semrush per controllare il posizionamento, quindi senza una doppia verifica non era possibile capire se il risultato era veramente stato influenzato
- A detta dell’autore, erano stati usati massivamente clickbot (e vabbè), ma anche proxy pubblici scrapati, che sicuramente anche Google è in grado di individuare. Il servizio che abbiamo usato noi aveva esclusivamente proxy privati.
Che cosa ha funzionato (ed è interessante):
- il test ha influenzato massivamente google trends
- il test ha influenzato google keyword planner, segno che con un po’ di volontà (e soldi) è possibile creare dei trend fittizi
- il test ha influenzato google analytics e google webmaster console, segno che chiunque (con un po’ di volontà e soldi) può sfalsare risultati… e visto che Google ha voluto introdurre il not provided, un consulente imbroglione potrebbe simulare traffico organico (che non converte) e farsi comunque pagare.

