
Ieri Michele Farinelli ha ricordato ad Alessandro Martin la questione discussa al Convegno GT durante la SEO War sull’internal server error del file robots.txt.
In questo post su FroggyBit Michele riassume la questione.
In sala dopo quella affermazione ci furono parecchie discussioni sulla veridicità o meno, ma soprattutto è importante precisare che l’affermazione parlava solo di Errore 50x restituito esclusivamente dal file Robots.txt. Lo scenario è dunque quello dove il sito continua a funzionare correttamente, mentre il file Robots.txt risulta inaccessibile.
@farinellim Grazie per avermelo ricordato. Il test sul fenomeno descritto da @enricoaltavilla comincia ora 😉 ubersuggest.org/robots.txt
— [email protected] (@esaurito) January 13, 2013
Quindi il test è iniziato su Übersuggest, un sito decisamente autorevole.
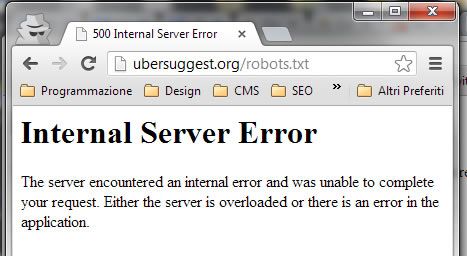
e di seguito la risposta HTTP per ulteriore conferma.
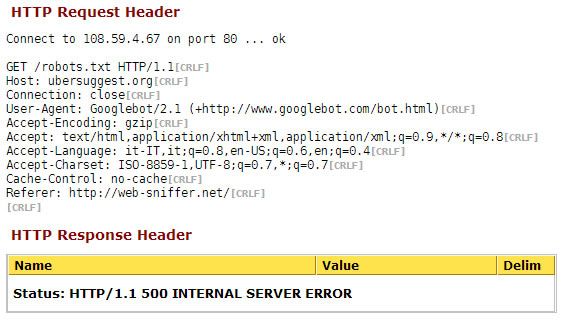
Oltre a queste due cose segnalo anche la presenza di una voce all’interno degli strumenti per Webmaster che possono effettivamente avvalorare la tesi di Enrico.
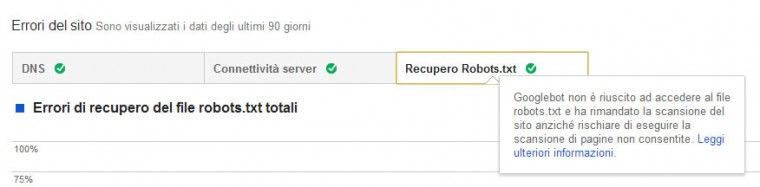
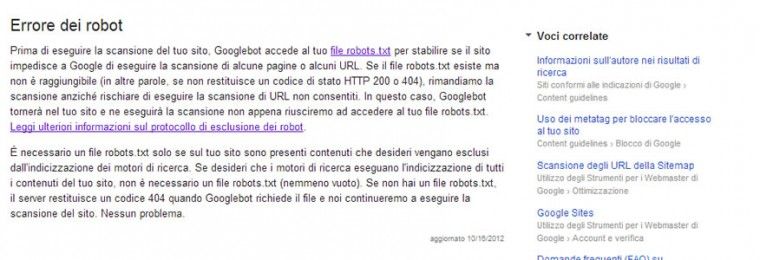
Secondo voi cosa succederà?
È stata aperta anche una discussione sul Forum gt.
In SERP per ora non si notano mutamenti come potete osservare nella seguente immagine.
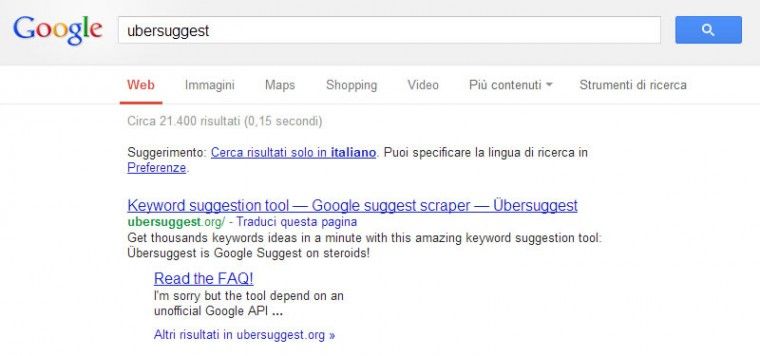
Giorno 21/01/2013 – Conclusione del test. Il commento di Alessandro.
Eccomi con la mia riflessione, come promesso.
Dopo alcuni giorni dall’attivazione dell’errore 500 sul robots.txt ho ricevuto un messaggio da GWT che mi diceva:
>“Over the last 24 hours, Googlebot encountered 6 errors while attempting to access your robots.txt. To ensure that we didn’t crawl any pages listed in that file, we postponed our crawl”
Quel “we postponed our crawl” mi ha fatto riflettere un po’. Il motore di ricerca si trova a non sapere se può o non può accedere alle pagine del sito, quindi nell’indecisione aspetta.
Se questa situazione perdurasse nel tempo il motore di ricerca si troverebbe in una situazione simile a quella che si presenta quando una risorsa indicizzata viene bloccata dal robots.txt con Disallow. Google da un certo punto in poi non può più dire se il contenuto che ha indicizzato corrisponde o meno all’attuale contenuto della risorsa e quindi non può più fidarsi dei fattori onpage per stabilirne la rilevanza [1]. Quindi usa i fattori offsite e continua a mostrare in SERP quelle risorse di cui conosce la URL perché prendono almeno un backlink esterno.
Poniamo che io adesso sostituisca a Ubersuggest un sito porno. Se Google non lo deindicizzasse a seguito dell’errore 500 sul robots.txt, migliaia di utenti che cercano Ubersuggest facendo query navigazionali finirebbero su un sito molto diverso da quello che si aspettavano.
Insomma più ci penso e più mi convinco che se Google non prendesse provvedimenti seri verso un sito che eroga 500 sul robots.txt si esporrebbe a problemi seri che comprometterebbero la qualità delle SERP. Mi aspetto che il tipo di provvedimento dipenda moltissimo da quanto un sito risulta “vivo” agli occhi di Google, ovvero capace di attrarre link e citazioni spontanee. Ubersuggest è un sito che viene quotidianamente citato e linkato su Twitter e sul resto del web pertanto ipotizzo che i segnali offsite siano talmente forti che inducano Google ad aspettare prima di prendere provvedimenti. Prima o poi però la una forma di svalutazione (de indicizzazione o altro) arriverà.
[1] Ovviamente nessuno sa se questo è vero ma il buon senso e l’osservazione sembrano confermarlo, ho messo l’accento sulla rilevanza perché credo che Google difficilmente “dimentichi” completamente qualcosa se può trarne informazioni utili. Quindis e magari non usa le vecchie informazioni sul contenuto di una pagina per stabilirne la rilevanza magari le usa in qualche altro modo.?

Sono davvero curioso di vedere l’esito di questo test. Io credo che effettivamente un errore 50X possa davvero provocare la deindicizzazione di un intero sito…
A mio avviso, essendo il robots.txt del tutto facoltativo, lo spider continuerà ad indicizzare l’intero sito, come le prime verifiche sembrano confermare…
Intanto Googlebot si è imbizzarrito e da ieri ha fatto 352 richieste al robots.txt.