

Per chiarezza sotto riporterò gli embed post di Google+ che riepilogano gli avvenimenti, ma già in questo post farò un breve sunto dell’esperimento.
Step 1 – La scoperta del noindex in un robots.txt di Google
Di seguito un estratto e l’immagine di un post su g+ dove viene identificata la direttiva Noindex:.
Here is the story. Not many people know that until some time ago Google supported a proprietary out-of-standard robots.txt instruction called “noindex”.
The robots exclusion standard doesn’t contemplate an instruction named “noindex” in the robots.txt file. Robots meta tags and X-Robots HTTP headers have that instruction, of course, but not the robots.txt file.
There is a good reason about the absence of a noindex directive within a robots.txt file: the goal of this file has never been to manage search engine indexing but only search engine crawling, which are two extremely different things.
In Google intentions, the noindex directive in the robots.txt file works exactly as a normal noindex directive used in a specific page, the only difference is that in the robots.txt file you could ask for entire directories to not be indexed.
The additional advantage of the robots.txt version of this directive is that a noindex directive contained in the HTML code of a resource can be seen by the spider only if it downloads the resource and reads its code. The noindex directive in the robots.txt file, instead, is immediately acquired and the spider doesn’t need to ask for the resource that you don’t want to be indexed…
Enrico Altavilla
Che tradotto liberamente per il nostro pubblico italiano:
C’è una buona ragione per cui è corretto non avere una direttiva noindex nel file robots.txt: l’obiettivo del file non è mai stato relativo alla gestione dell’indicizzazione, ma solamente alla gestione del crawling, che sono due cose molto differenti.
Nelle intenzioni di Google, l’uso del noindex nel file dovrebbe avere lo stesso funzionamento del noindex all’interno delle singole pagine, ma con la sola differenza di permettere la deindicizzazione di intere directory.
Il vantaggio ulteriore di avere una direttiva noindex all’interno del robots.txt è di consentire l’effetto dell’istruzione senza la necessità di scaricare la risorsa e leggerne il contenuto. In questo modo infatti la direttiva viene subito recepita e di conseguenza si può indicare la non indicizzazione senza far accedere la risorsa.
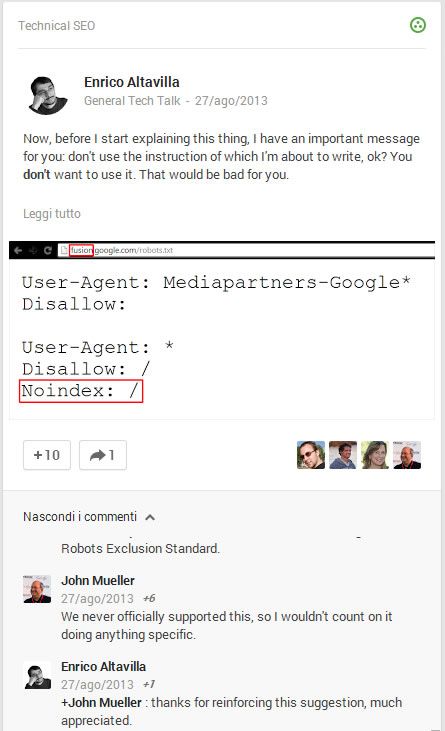
La cosa molto interessante è poi la risposta di John Mueller di Google:
We never officially supported this, so I wouldn’t count on it doing anything specific.
John Mueller
Step 2 – Introduzione della direttiva Noindex: / all’interno del robots.txt di seomantical.com
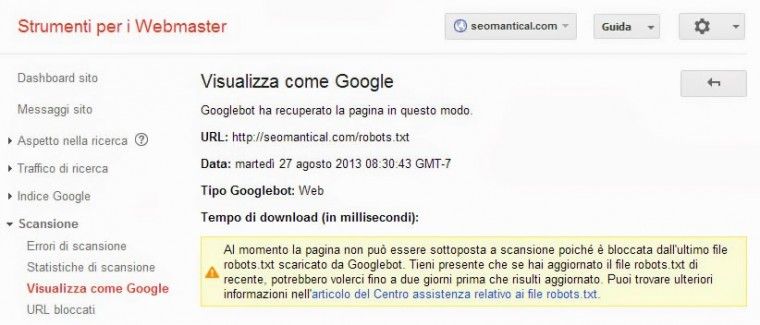
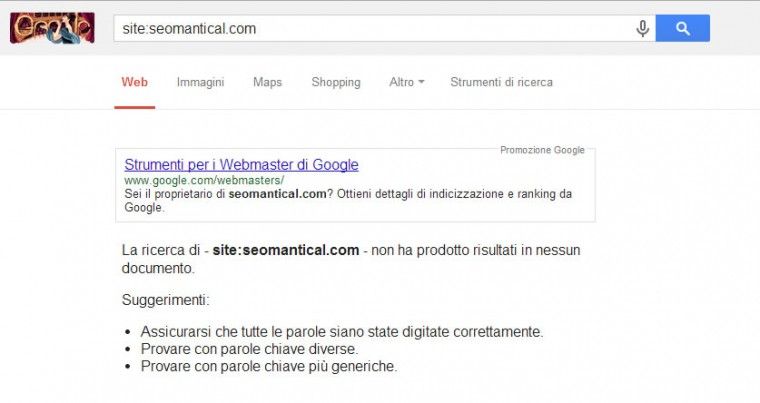
Ho aggiunto il sito seomantical.com a Google Webmaster Tool e ho inviato per la scansione il file robots.txt ottenendo il messaggio di impossibilità di scansione.
Al momento la pagina non può essere sottoposta a scansione poiché bloccata dall’ultimo file robots.txt scaricato da Googlebot.
Il file robots.txt del sito è il seguente:
User-Agent: * Noindex: /
Da notare che in realtà non c’è nessuna direttiva di Disallow nel file robots.txt e che il sito al tempo era completamente indicizzato (anche se nello screenshot già si vedono gli effetti della direttiva non-standard):
Come riprova del messaggio ricevuto da webmaster tools si rende dunque necessario approfondire la situazione per vedere il comportamento del bot.
Step 3 – Controllo dei log del web server – nello specifico il comportamento di Googlebot
66.249.72.77 - - [11/Aug/2013:15:23:00 +0200] "GET /robots.txt HTTP/1.1" 404 340 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.77 - - [11/Aug/2013:15:23:00 +0200] "HEAD /amante-della-seo-4.html HTTP/1.1" 200 - "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.77 - - [11/Aug/2013:15:23:00 +0200] "GET /amante-della-seo-4.html HTTP/1.1" 200 413 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.77 - - [11/Aug/2013:15:59:10 +0200] "GET / HTTP/1.1" 200 939 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.77 - - [11/Aug/2013:16:08:20 +0200] "GET /min/?g=css HTTP/1.1" 200 4222 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.65 - - [13/Aug/2013:06:05:36 +0200] "GET /robots.txt HTTP/1.1" 404 340 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.65 - - [13/Aug/2013:06:05:37 +0200] "GET / HTTP/1.1" 200 939 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.65 - - [13/Aug/2013:06:10:13 +0200] "GET /min/?g=css HTTP/1.1" 200 4222 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.65 - - [13/Aug/2013:14:30:33 +0200] "GET /robots.txt HTTP/1.1" 404 340 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.65 - - [13/Aug/2013:14:30:33 +0200] "GET /net HTTP/1.1" 200 1199 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.65 - - [13/Aug/2013:16:18:59 +0200] "GET /page HTTP/1.1" 200 1219 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 88.231.30.49 - - [17/Aug/2013:16:48:46 +0200] "HEAD /?author=1 HTTP/1.1" 400 - "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.77 - - [22/Aug/2013:16:27:29 +0200] "GET /robots.txt HTTP/1.1" 404 340 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.77 - - [22/Aug/2013:16:27:29 +0200] "GET / HTTP/1.1" 200 939 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.77 - - [22/Aug/2013:16:29:17 +0200] "GET /min/?g=css HTTP/1.1" 200 4222 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.77 - - [22/Aug/2013:22:09:00 +0200] "GET /robots.txt HTTP/1.1" 404 340 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.65 - - [24/Aug/2013:10:28:05 +0200] "GET /robots.txt HTTP/1.1" 404 340 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.65 - - [24/Aug/2013:10:28:05 +0200] "GET /net/reversedns HTTP/1.1" 200 1045 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.65 - - [24/Aug/2013:10:34:05 +0200] "GET /page/nofollow HTTP/1.1" 200 1033 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.65 - - [24/Aug/2013:11:12:39 +0200] "GET /min/?g=css HTTP/1.1" 200 4222 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.65 - - [24/Aug/2013:11:12:40 +0200] "GET /land/images/jquery.png HTTP/1.1" 200 1182 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.65 - - [24/Aug/2013:11:12:41 +0200] "GET /land/css/images/alert-overlay.png HTTP/1.1" 200 135 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.65 - - [24/Aug/2013:11:12:41 +0200] "GET /land/css/images/bc.png HTTP/1.1" 200 327 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.65 - - [24/Aug/2013:11:12:42 +0200] "GET /land/images/html5.png HTTP/1.1" 200 6397 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.65 - - [24/Aug/2013:11:12:43 +0200] "GET /land/css/images/page.png HTTP/1.1" 200 2681 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.65 - - [24/Aug/2013:11:12:44 +0200] "GET /land/images/blueprint.png HTTP/1.1" 200 2117 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.65 - - [24/Aug/2013:11:12:45 +0200] "GET /land/images/codeigniter.png HTTP/1.1" 200 1118 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.65 - - [24/Aug/2013:12:14:22 +0200] "GET /net/whois HTTP/1.1" 200 1011 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.65 - - [25/Aug/2013:11:49:53 +0200] "GET /robots.txt HTTP/1.1" 404 340 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.65 - - [25/Aug/2013:11:49:54 +0200] "GET / HTTP/1.1" 200 939 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.65 - - [26/Aug/2013:02:12:42 +0200] "GET /robots.txt HTTP/1.1" 404 340 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.65 - - [26/Aug/2013:02:12:43 +0200] "GET /min/?g=css HTTP/1.1" 200 4222 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.65 - - [26/Aug/2013:21:16:16 +0200] "GET /robots.txt HTTP/1.1" 404 340 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.65 - - [26/Aug/2013:21:16:16 +0200] "GET /page/inspector HTTP/1.1" 200 1003 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.65 - - [27/Aug/2013:14:54:13 +0200] "GET /robots.txt HTTP/1.1" 200 45 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.72.77 - - [27/Aug/2013:22:10:38 +0200] "GET /robots.txt HTTP/1.1" 200 45 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.75.77 - - [30/Aug/2013:20:22:43 +0200] "GET /robots.txt HTTP/1.1" 200 45 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)" 66.249.75.65 - - [31/Aug/2013:04:51:01 +0200] "GET /robots.txt HTTP/1.1" 200 45 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +https://www.google.com/bot.html)"
Notare come dal 27 Agosto il comportamento di Googlebot sia cambiato.
Step 4 – L’attesa e la lenta de-indicizzazione in corso
Il sito in questione era composto di pochissime pagine e dunque risulta molto semplice controllare la scomparsa di particolari URL. La prima pagina rimossa è stata la Home Page per poi lentamente rimuovere anche le altre.
Per mostrare una riprova prendo una SERP dove apparivano pagine che ora non sono più presenti.
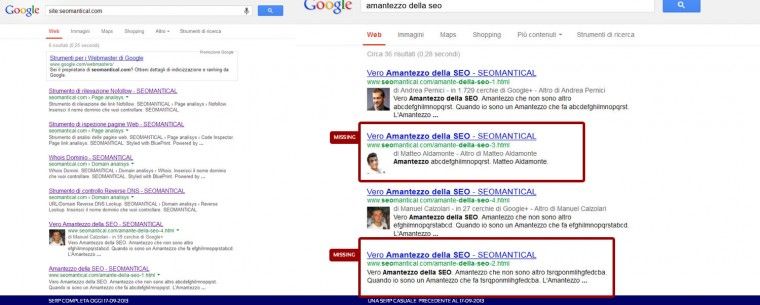
Di seguito embeddo il post su Google+ in modo da poter anche leggere alcuni degli interessanti commenti e le elaborazioni/supposizioni fatte al momento.
Conclusione – Il Noindex nel file robots.txt funziona
Cosa abbiamo imparato da questo esperimento oltre alla teoria, che è sempre bene conoscere.
Nonostante l’affermazione di John Mueller e nonostante quello che ci dice il buon senso spesso la realtà di come funzionano le cose è differente. Nella SEO il pensiero critico è una necessità che ci deve contraddistinguere e ci deve portare a sperimentare, analizzare, provare e confutare le teorie e le regole imposte dalle linee guida.
Per riuscire a comprendere il funzionamento delle cose è necessario toccare con mano, soprattutto perché Google tende a fare spesso un po’ come vuole lui…mascherato da paladino del web libero, standard compliant, cacciatore di streghe e W3Ciaro.
Ogni verità è un percorso tracciato attraverso la realtà.
Henri Bergson, Le due sorgenti della morale e della religione, 1932 – https://bit.ly/16aYf2J
Aggiornamento finale e de-indicizzazione totale – 02-12-2013



Aggiungo i risultati di un mio piccolo test.
Mi è capitato che una parte delle pagine di ADworld Experience fosse stata indicizzata erroneamente da Google con il protocollo https, anzichè con l’http semplice.
Sul sito però non c’è alcun certificato e quindi il motore ha cominciato a dare errore di certificato scaduto/inesistente.
Oltre a fare un redirect dalla versione https a http nell’htaccess e provare inutilmente di rimuoverli dall’indice attraverso il GWMT, dopo aver letto il post altavilliano/pernicioso ho pensato di testare anche io se la direttiva noindex poteva accelerare la deindicizzazione delle pagine errate.
A distanza di oltre una settimana però le pagine con https si sono dimezzate, ma molte sono ancora lì, quindi la cosa sembra essere dovuta più al normale processo di redirect del robots, che alla direttiva noindex, che, in questo caso, sembra essere stata ignorata.
My 2 cents… 😉
In realtà se hai messo quel robots, da come l’ho testato io tutto quello che avviene dopo non verrebbe recepito.
Quindi redirect e altre cose vengono vanificati.