Dopo l’eccezione fatta Martedì scorso a causa della guida sulla migrazione ad HTTPS ecco che riparte #SemanticSEOWut con il suo 8° appuntamento.
Ma passiamo come al solito alle notizie che meritano una lettura.
#1 Rilasciato Schema.org 1.9 con delle interessanti aggiunte
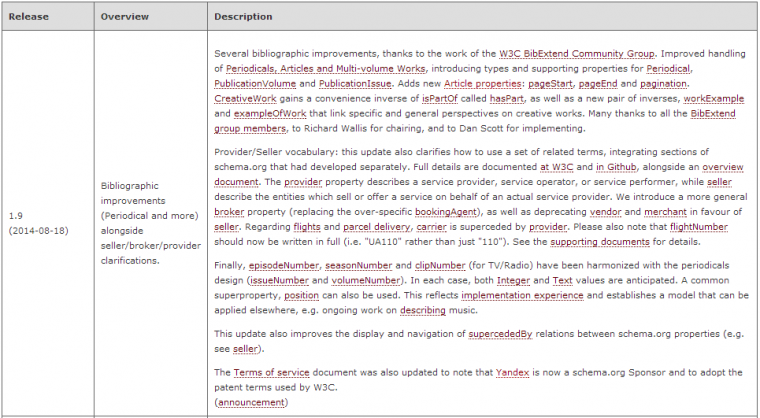
Grazie a Jarno Van Driel per la segnalazione.
#2 Wikisearch: API di ricerca semantica
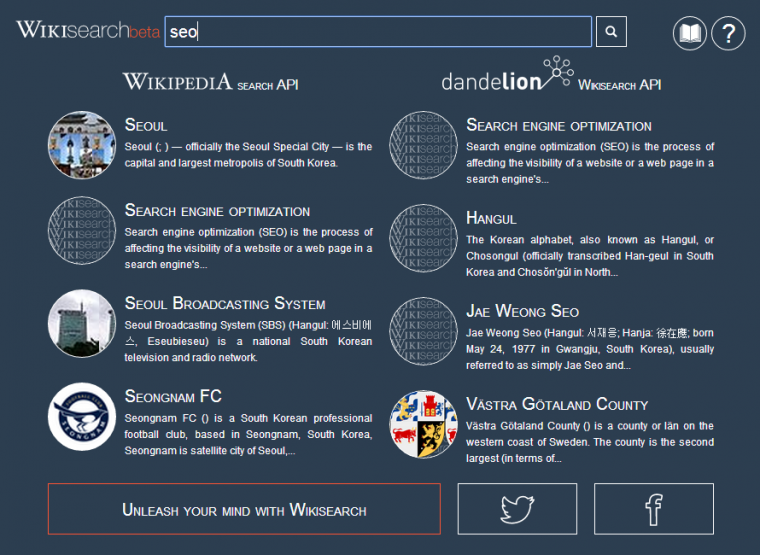
Riporto la descrizione fornita sul sito di WikiSearch.
Wikisearch is a semantic search API that helps you find the specific Wikipedia page you’re looking for. It’s designed to work even if you don’t remember its exact title, or have only a vague remembrance that it relates to some specific topic.
For example, say you’ve heard about the Game of Thrones TV series, but you want to know the book on which it’s based. With Wikisearch, you can search for screenplay game of thrones and it will lead you to the Wikipedia page titled A song of ice and fire, even if you had no clue about what the name of the book was.
Wikisearch can understands semantic relationships between different things and concepts. For instance, it understands that Westminster church and Westminster abbey refer to the same thing, even though they are spelled differently.
Wikisearch is specially useful in auto-complete scenarios where the user can typically examine only the first few search results before taking a decision. By filtering out things like disambiguation pages and providing content that is semantically relevant to the search at hand, it can significantly improve overall user experience.
#3 OpeNER project: Natural Language Processing per tutti
Grazie a Jan Willem-Bobbink scopriamo questo strumento open-source finanziato dalla Commissione Europea.
Anche qui riporto la descrizione del sito ufficiale:
OpeNER is a project funded by the European Commission under the FP7 (7th Framework Program). Its acronym stands for Open Polarity Enhanced Name Entity Recognition.
OpeNER’s main goal is to provide a set of ready to use tools to perform some natural language processing tasks, free and easy to adapt for Academia, Research and Small and Medium Enterprise to integrate them in their workflow. More precisely, OpeNER aims to be able to detect and disambiguate entity mentions and perform sentiment analysis and opinion detection on the texts, to be able for example, to extract the sentiment and the opinion of customers about certain resource (e.g. hotels and accommodations) in Web reviews.
Secondo me son cose belle quelle di questo ottavo appuntamento.