
Capita di rado nella vita di un SEO di poter fare le cose come Googlebot comanda. Quando si lavora per altri, anche nella migliore e più idilliaca delle situazioni, le difficoltà di comunicazione lasciano sempre spazio a piccoli o grandi buchi o incomprensioni.
Più grande poi diventa il numero delle persone coinvolte, più difficile è tenere sotto controllo gli aspetti SEO e svilupparli a regola d’arte. Si finisce sempre per andare in produzione con le pezze da mettere.
Ho però oggi la fortuna di potervi parlare di un caso in cui, finalmente, sono riuscito a fare le cose come dicevo io.
Il contesto in breve
Il progetto è uno di quelli che nasce “in famiglia”: il sito si chiama 33 mani ed è un ecommerce di prodotti di artigianato artistico realizzati da aziende del solo Trentino.
Nasce per idea di Elisa Poli che dopo un’esperienza di lavoro nel campo del restauro del legno, sceglie di farsi forte delle competenze del marito e della conoscenza del territorio per aiutarla a lanciare un progetto web destinato a durare.
Si parte da zero, senza alcun link in entrata. Le risorse di tempo sono limitate, quelle di denaro pure: bisogna concentrarsi sulle cose che contano davvero. La libertà d’azione è però totale.
Voglio quindi ripercorrere con voi quelli che sono stati i primi passi di 33 mani su Google, facendo una cronaca del lavoro svolto fin qua.
La progettazione del sito
Prima di tutto un po’ di nozioni tecniche di base. Il sito è sviluppato in Magento. Il template è responsivo e realizzato su misura con Bootstrap 3.
L’architettura del contenuto è stata progettata appoggiandosi principalmente ad un mega menu orizzontale, che si divide in macro categorie merceologiche (Arredo, Oggettistica, Accessori ed in futuro anche Gioielli), ma ci da la possibilità di declinarle non solo per sottocategoria, ma anche per materiale (es. “complementi d’arredo in legno”) o altri generi di categoria trasversale (es. “candele per matrimonio”).
Fanno eccezione i link dedicati ai materiali ed agli artigiani, presenti solo nella parte bassa dell’homepage e come riquadro contestuale della pagina prodotto.
Per tutti questi tipi di contenuto si è scelto di utilizzare le categorie di Magento, la cui parte di CMS è notoriamente molto grezza. Le categorie permettono invece di associare i singoli prodotti a pagine tematiche, inoltre sono strutturate gerarchicamente a livello di costruzione dell’URL. Sono anche ben supportate dal rel canonical nativo (ma su questo spenderò alcune parole più avanti).
Le pagine di categoria presenti al momento sono limitate ai prodotti in assortimento. La scalabilità è massima, man mano che il catalogo verrà ampliato aumenteranno anche le pagine ottimizzabili.
Robots.txt o noindex?
Per scelta, il sito non dispone di un file robots.txt. Il controllo di ciò che viene pubblicato sul motore di ricerca è lasciato al meta robots (index/noindex).
Il motivo di questa scelta? Sono molteplici. Innanzi tutto non volevo essere scocciato da Bing (che in diversi casi vissuti ha mostrato di imbizzarrirsi proprio sul file robots.txt): beccati un 404 e vattene via.
In secondo luogo, non voglio dare informazioni sulla struttura di eventuali cartelle amministrative o sulla posizione della sitemap (nulla che uno scraper non sappia individuare con un minimo di sforzo, ma perché rendergli la vita facile?).
In terzo luogo, perché voglio che l’indicizzazione sia veloce e non abbia colli di bottiglia potenzialmente dannosi (vedi anche questo recente video di Matt Cutts). Può darsi che in futuro si verificheranno casi in cui sarà necessario avere un file robots.txt strutturato, ma non adesso.
Infine, il noindex permette una risposta molto più veloce del motore quando una pagina cambia status (ho una chicca da darvi in merito, aspettate la fine).
Gestione del contenuto duplicato
Il problema più critico in fase di lancio, in particolar modo per un ecommerce, è… aiutatemi a dirlo? Quello del contenuto duplicato.
Su 33 mani ci sono essenzialmente due cause potenziali di contenuti duplicati, una di natura editoriale ed una di natura strutturale:
- ci sono alcune categorie con contenuti pressoché identici (l’assortimento è ancora limitato ed in alcuni casi ci sono delle sovrapposizioni)
- Magento ha una gestione molto “allegra” degli URL prodotto. Prima del nome del prodotto, mette tutto il percorso delle cartelle a seconda di dove si trova l’utente: /it/prodotto nel caso della home, /it/categoria/prodotto nel caso della categoria, ma la cosa vale anche per eventuali sottocategorie, che generano sottocartelle a cascata.
La duplicazione editoriale delle categorie ho scelto di gestirla con il meta robots (noindex, follow), mentre quella strutturale delle URL prodotto l’ho fatta gestire al rel canonical nativo di Magento, che fa il suo dovere (a chi interessa: l’opzione è presente in System > Configuration > Catalog > Search Engine Optimization).
E ora un po’ di cronistoria…
Fase di test
Il dominio è stato registrato nel luglio 2013. In un primo periodo è stato utilizzato in modo sbrigativo come piattaforma per fare i primi test, con la sola possibile precauzione di disabilitare l’accesso ai crawler per tutti i contenuti tramite robots.txt.
Il 17 febbraio 2014 il dominio è stato migrato su una nuova piattaforma di hosting. E’ stato rimosso il robots.txt, al posto del sito è stata pubblicata una semplice splash page, con meta robots noindex, follow.
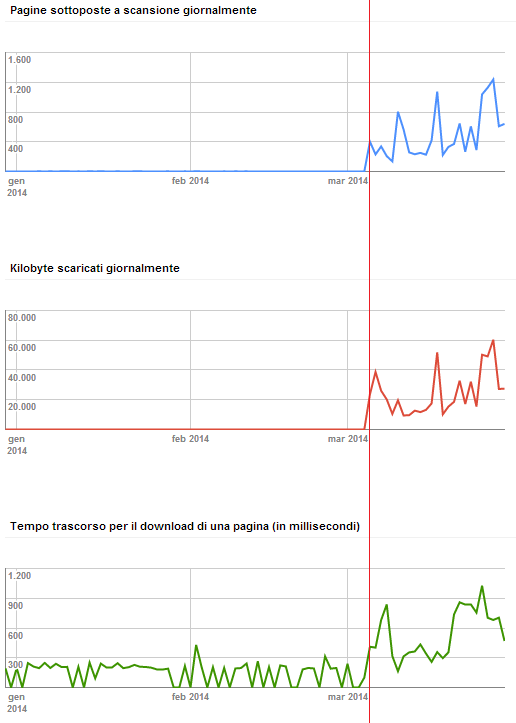
Immagine 1: Le statistiche di scansione di Google Webmaster Tools. In rosso il go live.
In produzione!
33 mani è andato live il 5 marzo 2014, verso le 21.00, con le impostazioni di index, follow già configurate come detto sopra.
Il sito è stato quindi collegato alla pagina di Google+ (e viceversa: la consueta procedura di verifica del publisher).
La mattina del 6 marzo, il sito risultava già perfettamente indicizzato su Google (82 pagine visibili per la query [site:33mani.com]), con una visibilità di base per query di coda lunga ed una posizione da prima pagina per la query di brand [33 mani].
Nel corso della giornata il risultato della query di brand si è spostato fino a raggiungere la seconda posizione.
Nella serata, verso le 21.00 è stata poi generata la sitemap.xml, inviata tramite Google Webmaster Tools.
Il giorno seguente arrivano le prime conferme e le prime soddisfazioni: Google sembra aver recepito correttamente la natura di brand della query [33 mani] (vedi immagine).
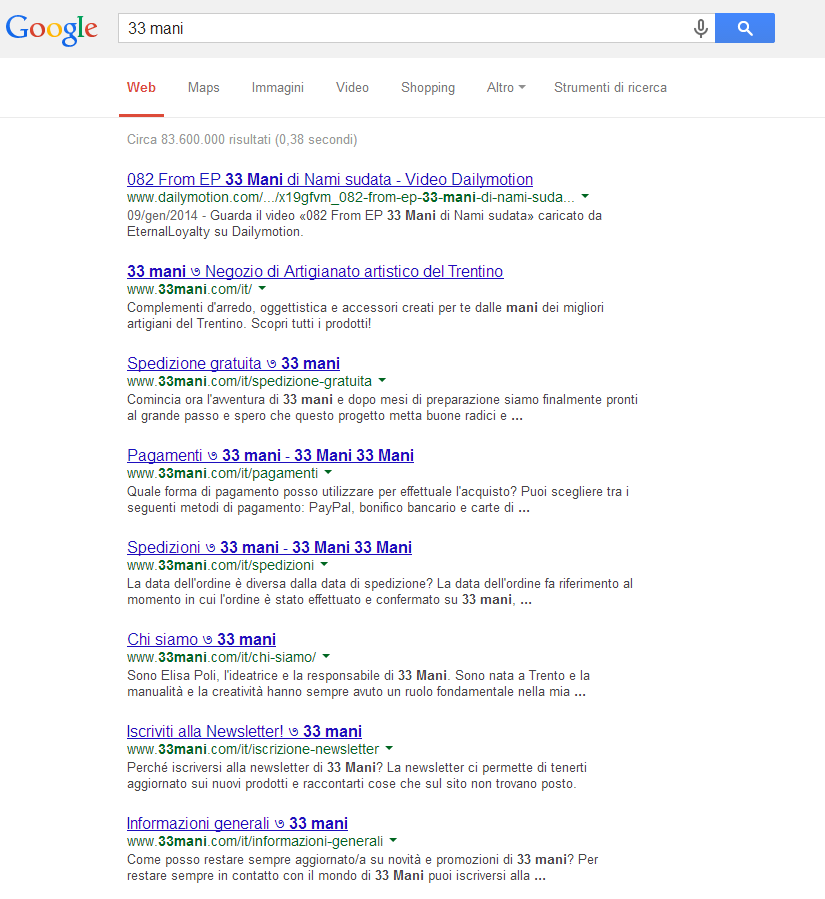
Immagine 2: i primi risultati con la query di brand [33 mani]
Inoltre, risultano visibili già 152 pagine per la query [site:33mani.com]. Un buon risultato se consideriamo che il sito appena pubblicato ne contava poco meno di 300.
Meno di due settimane dopo, il 16 marzo, la query di brand risulta perfettamente compresa e appaiono i sitelink (vedi immagine).
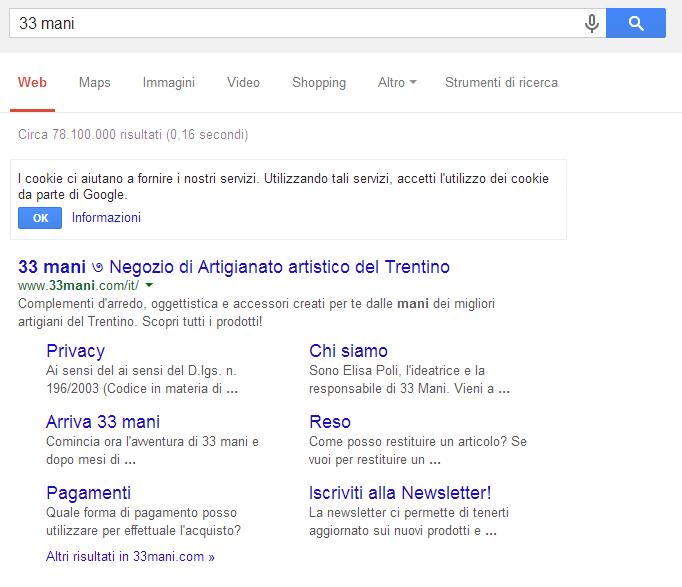
Immagine 3: Query di brand completa di sitelink
Tutte le pagine del sito risultano infine visibili per la query [site:33mani.com]. A parte qualche svista sfuggita ai primi controlli, non risultano duplicati nei risultati di ricerca.
La fase di indicizzazione è finita qua e pure io mi fermo. La struttura del sito è pronta per scalare assieme all’arrivo di nuovi contenuti, Google ha risposto esattamente come volevo e non potrei essere più soddisfatto di così.
Ora è questione di… aiutatemi a dirlo? Linketti. Linketti, linketti…
Piccole lezioni imparate
Il lavoro di indicizzazione e pubblicazione di 33 mani su Google mi ha permesso ti scovare due chicche un po’ nascoste che riporto in fondo all’articolo come bonus per chi ha avuto la pazienza di seguire fino qui.
1. Collegate sempre la pagina di G+
In particolar modo immediatamente dopo il lancio di un sito nuovo. Cosa succede quando collegate la pagina? State chiedendo nient’altro che un reinvio all’indice. Googlebot andrà prontamente a scaricare la pagina, poi la passerà al parser per verificare se nel sorgente HTML è presente l’istruzione rel=publisher.
E se trova nuovi link interni, con una struttura ben progettata… è subito festa. Come abbiamo visto, in una notte, senza l’ausilio di particolari accorgimenti tecnici già aveva pubblicato un’80ina di pagine.
2. Entrare nei risultati nel giro di pochi secondi
In un caso avevo una pagina di categoria che avevo ottimizzato, ma per diverse ragioni lasciato con istruzione meta robots noindex, follow. Ad un certo punto le condizioni per lasciarla non pubblicata erano venute a cadere, pertanto ho rimosso l’istruzione meta robots.
Ho quindi fatto un Visualizza come Googlebot + Reinvia all’indice tramite Google Webmaster Tools. Dopo un minuto (o forse anche meno!) la pagina era già presente tra i risultati di Google.
Questo perché, giova ribadirlo, l’istruzione noindex significa “non indicizzare”, ma viene usata da Google come “scansiona pure, ma non pubblicare”. Era una cosa che sapevo già, ma non mi aspettavo un tempo di risposta così breve.



Ottimo articolo, se posso qualche domanda, dici che non hai usato robots.txt ma che il meta nofollow, come hai fatto a nascondere le cartelle di amministrazione etc?
Ciao Andrea! Semplice: non le ho linkate da nessuna parte.
Quand’anche dovesse capitare che Google trovi un URL proveniente da una sezione privata del sito (perché inavvertitamente linkata in una pagina pubblica), sbatterà contro un form di login senza alcun link al sito… di fatto, una pagina orfana.
Non esiste quindi alcun rischio che Google trovi la struttura delle URL dell’area di amministrazione e si metta a tentare di indicizzarla… perché per fortuna l’area di admin di Magento è progettata bene.
Bloccare a Googlebot l’area di amministrazione ha davvero senso qualora sia progettata male (nel caso in cui abbia ad esempio i link del menu di navigazione in chiaro).
In linea generale, questa è la linea guida da seguire: https://developers.google.com/webmasters/control-crawl-index/docs/faq?csw=1#h13
Piuttosto: la tua osservazione mi ha permesso in via del tutto coincidentale di trovare una falla da tappare che non avevo avuto modo di valutare all’atto pratico.
La ricerca interna di Magento genera pagine indicizzabili ed è linkabile dall’esterno tramite link diretto. Questo espone il sito a potenziali attacchi che potrebbero rivelarsi fastidiosi nelle mani sbagliate di qualcuno che linka il sito dall’esterno, con termini (diciamo così) non pertinenti.
Grazie quindi della tua osservazione 🙂
(se vai a vedere il robots.txt ora, vedrai cos’è cambiato e potrai trarre le dovute conclusioni)
Pensandoci bene era quasi ovvio.
Come faccio a vedere il tuo robots?
Lo trovi dove stanno i robots.txt di solito, ovvero nella directory radice (/robots.txt)